商业范儿
商业范儿8月11日,百川智能发布开源医疗增强大模型Baichuan-M2。OpenAI于8月6日开源两款大模型,主打部署成本超低和医疗能力最强,但百川开源更小尺寸模型并实现医疗能力反超,在所有开源模型中登顶世界第一。
今年1月,百川在行业内首发“AI患者模拟器”,用真实数据构造上万个不同年龄性别症状的AI患者,模拟了数百万次诊疗过程,基于该范式开源的Baichuan-M1,为行业首个医疗增强模型。7个月后,百川升级患者模拟器并引入模型端到端强化学习,训练的Baichuan-M2在HealthBench等评测上取得更大突破。
更低成本爆发更大性能
OpenAI自2024年下半年起将医疗作为模型能力提升的首要方向,投入大量人力算力精力。今年5月,OpenAI发布权威且贴近真实临床场景的HealthBench医疗健康评测集。这个包含了5000个逼真多轮医疗对话的评测集,代表了OpenAI在医疗领域重点突破的决心。开源gpt-oss系列模型过程中,OpenAI首次将医疗作为第一重要的评测标准;发布GPT-5时,请到现场的唯一使用者是抗癌患者,医疗是大模型最有前景最具价值的方向,正成为头部企业的共识。
Baichuan-M2在HealthBench上得到60.1的高分,以32B的较小尺寸不仅反超OpenAI 最新开源模型gpt-oss120b(得分57.6),更是力压Qwen3-235B、Deepseek R1、Kimi K2等当前世界所有开源大模型。
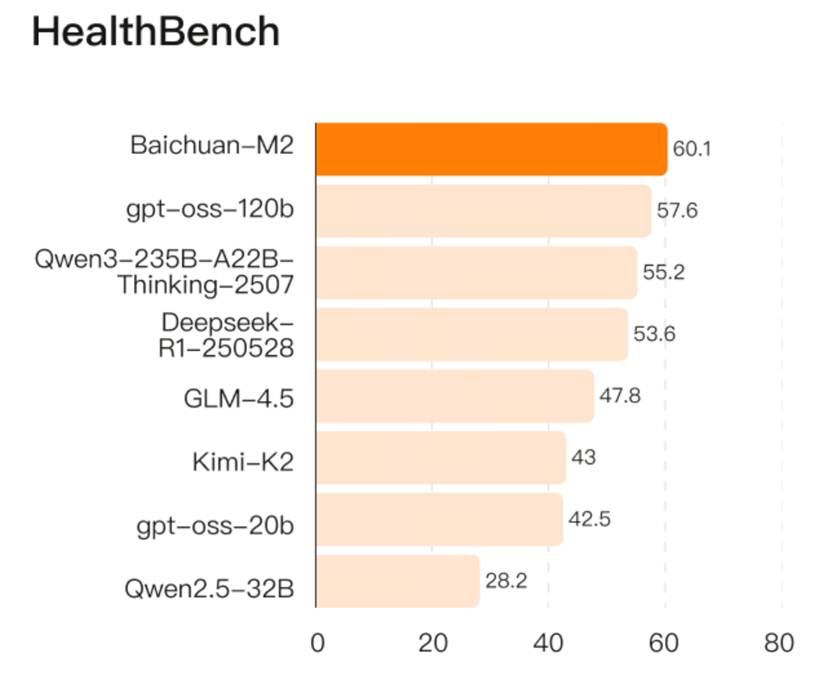
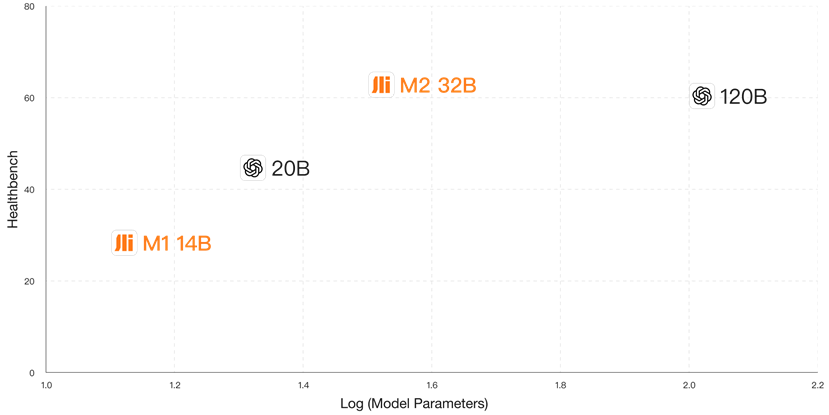
针对医疗领域用户隐私考虑下的模型私有化部署需求,百川智能对Baichuan-M2进行了极致轻量化,量化后的模型精度接近无损,可以在RTX4090上单卡部署,相比DeepSeek-R1 H20双节点部署的方式,成本降低了57倍。针对国产主流芯片的开发和适配,让多数医疗机构利用现有硬件条件既可实现快速部署。
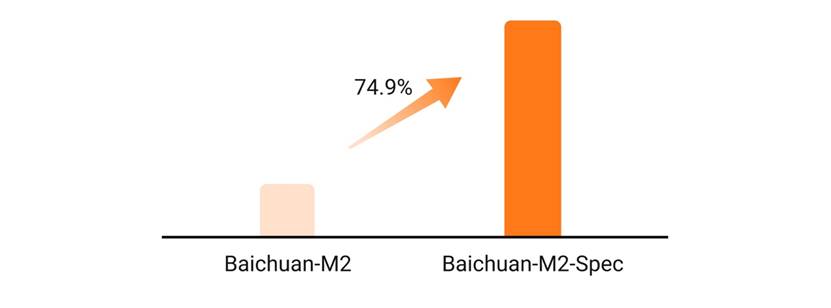
此外,面向急诊、门诊等对于交互速度要求更高的场景,基于Eagle-3架构优化的Baichuan-M2 MTP版本在单用户场景下实现了74.9%的token速度跃升。
医疗能力极大增强后,模型通用能力是否会下降?头部大模型企业主要用数学和代码数据进行强化学习,百川是首个将医疗数据用作强化学习的中国团队,同时也验证了高质量医疗数据对于模型通用能力的增长具有较高价值,M2模型在数学、指令遵循、写作等通用核心性能上不降反升,因此这个模型也可应用于医疗以外的其他领域。

医疗复杂问题比肩GPT-5
在大语言模型的发展中,“知识”与“能力”是两条相辅相成但又相对独立的主线,模型在医学考试(如 USMLE)上的表现被视为衡量医疗水平的重要指标,但随着题库饱和,这类选择题或短回复的评测难以反映模型的临床实用性,医疗 AI 并不等于“刷题机器”,分数再高也不意味着在真实医疗场景中好用。
OpenAI从HealthBench整体数据中选出1000个特别困难的复杂问题作为Hard子集,用于验证模型多维度、全景化解决疑难复杂医学问题的能力。GPT-5发布时OpenAI特别强调,其是HealthBench Hard评测全球唯一超过32分的模型。Baichuan-M2以34.7分成为全球第二款超过32分的模型,力压世界所有其他顶尖闭源大模型。
GPT-5发布时既没有开源,也没有公布参数,无法私有化部署,无法低成本应用。相比之下,Baichuan-M2快速免费开源,成为医疗行业低成本快速应用部署世界顶尖医疗模型的唯一选择。
百川技术团队在大型验证系统(Large Verifier System)、端到端强化学习、AI患者模拟器、多类型医疗数据用于深度推理等4个方面的创新探索,是Baichuan-M2模型取得飞跃式进步的关键。
过去一年,可验证奖励强化学习(RLVR)方法被头部大模型企业广泛使用,在数学、代码领域显著提升了模型性能。百川技术团队在这一过程中认识到,提高复杂现实问题的可验证性是进一步提升模型性能的关键,由此构建了大型验证系统,在通用验证器之外还设计了一套全面的医学验证系统。
人类医生在听取患者描述病情时,很容易分辨患者描述中的逻辑漏洞、从含混不清的表达中辨别出真实病因。现实中患者几乎无法全面准确表达自己的症状,仅基于静态的病例、指南等医疗数据训练,模型无法掌握人类医生的这一能力。为了突破这一瓶颈,百川技术团队升级迭代了今年初首创的AI患者模拟器。这个模型器是使用真实病例构建的AI系统,能够模拟千差万别的患者、症状、表达,特别是包含错误噪声的表达,最大程度还原了真实医疗场景。
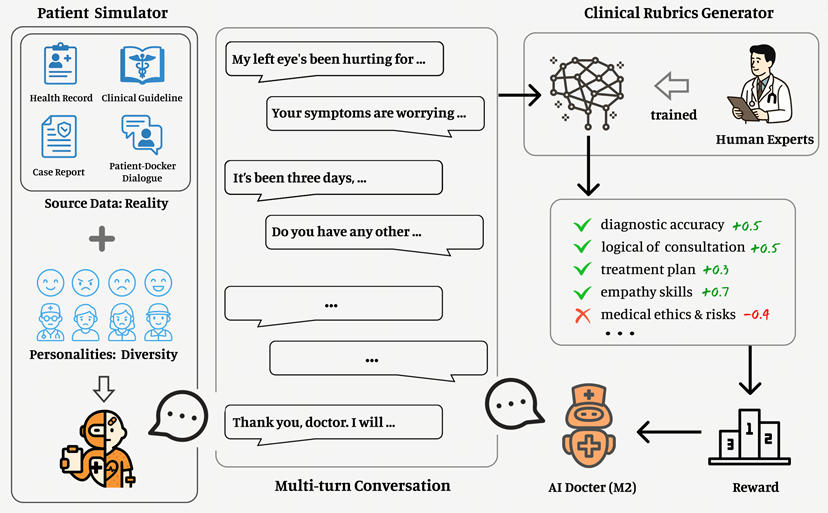
百川智能还构建了一个以天为频率更新的权威医学数据库,涵盖病例、论文、文献、指南、药学、生物学、合成数据等。为防止综合能力退化,采用医学数据、通用数据、数学推理数据2:2:1的比例,并引入领域自我约束训练机制,确保模型是一个具有通识、推理等综合能力的高水平医生,避免成为只会医学知识考试的高分者。
更符合中国临床诊疗场景
在中国临床诊疗场景的问题评测中,对比gpt系列模型,Baichuan-M2展现出更明显的可用性优势。百川从中国医学指南对齐、医疗政策适配和患者需求洞察等多个维度进行了深度优化,中国医疗机构和医生应用时,会明显感受到这一区别。
医疗大模型能否将全球医学知识、医学证据转化为符合本地优势特长的临床决策,也是为医生和患者提供切实服务能力的关键,Baichuan-M2为此所做的专门优化,让中国临床场景有了专属的顶尖模型。
今年2月,以Baichuan-M1为底座的AI儿科医生在国家儿童医学中心多学科会诊中获得会诊专家一致认可。M2在医疗沟通、诊断合理、检查合理、医疗治疗、医疗安全六个维度相较于M1均显著提升。
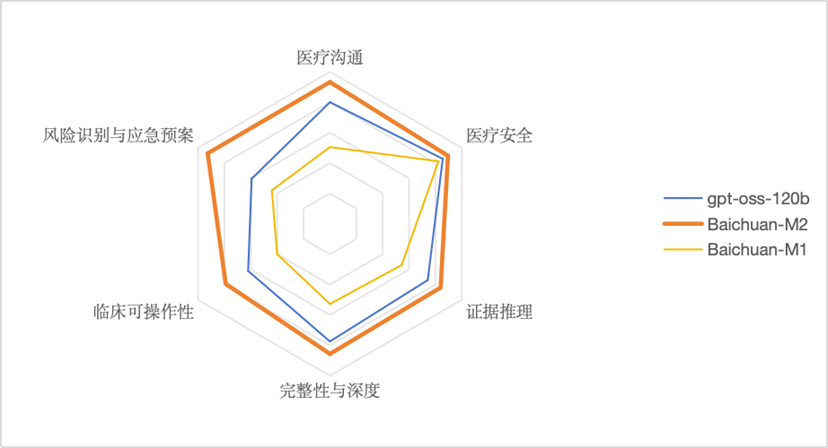
在北京市海淀区卫健委、北京大学第三医院、国家儿童医学中心等合作伙伴的支持下,M2在真实病例实测中体现出超强能力。国家儿童医学中心专家认为,M2在医学正确性、证据链推理、可操作性上展现出极强的专业性,在风险预警方面的表现可圈可点,关注到患儿有呼吸衰竭、心包填塞等风险,并给出应急方案。此外,它还将患儿既往血管瘤与当前病变联系,为医生打开了更广阔的思路。





















 GlobeNewswire
GlobeNewswire
 奶龙哥说游戏
奶龙哥说游戏
 常言道
常言道
 城刊快讯
城刊快讯
 大力财经
大力财经
 肩冲
肩冲

 路易斯
路易斯